go指南 - 官网
官网的文档,应该是最好的入门了吧
基础
每个 Go 程序都是由包构成的。
程序从 main 包开始运行。
一般包名与导入路径的最后一个元素一致。例如,"math/rand" 包中的源码均以 package rand 语句开始。
import (
"fmt"
"math"
)
// 上面这种导入方式更好
import "fmt"
import "math"如果一个名字以大写字母开头,那么它就是已导出的
如,math.pi就是未导出的,就没有定义,不能访问和调用。
math.Pi就导出了。导入一个包,只能引用已经导出的名字。
类型在变量名之后。
c的类型是定义在前面的。如果函数的参数是函数,或者返回值是函数,那么就会难以理解
int (*fp)(int (*ff)(int x, int y), int b) int (*(*fp)(int (*)(int, int), int))(int, int)go从后置类型的定义进化而来
x: int p: pointer to int a: array[3] of int 变成 x int p *int a [3]int用go写就是
f func(func(int,int) int, int) int f func(func(int,int) int, int) func(int, int) int但是指针的*是前置的
var p *int x = *p // 而不是 var p *int x = p*因为可能被理解为乘法
变量初始化如果赋值了,那么可以省略类型。具体被赋值成啥,看精度。如int,float64,complex128等等
在函数中,简洁赋值语句 := 可在类型明确的地方代替 var 声明。
:= 结构不能在函数外使用,只能用var
基本类型
bool
string
int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr
byte // uint8 的别名
rune // int32 的别名 // 表示一个 Unicode 码点
float32 float64
complex64 complex128
变量声明也可以“分组”成一个语法块。
没有明确初始值的变量声明会被赋予它们的 零值。
0,false,“”
类型转换
流程控制
for
Go 只有一种循环结构:for 循环。
基本的 for 循环由三部分组成,它们用分号隔开:
初始化语句:在第一次迭代前执行。仅在for作用域中可见。
条件表达式:在每次迭代前求值
后置语句:在每次迭代的结尾执行
可以省略分号变成while,甚至省略条件变成死循环。
if
不需要小括号,可以在前面加一个分号来执行简单语句。作用域就在if的范围内。
switch
相当于一大串的if-else。只运行选定的case,因为自动提供了break。
switch 的 case 语句从上到下顺次执行,直到匹配成功时停止。
不加条件的switch能看起来更清楚。
defer
defer 语句会将函数推迟到外层函数返回之后执行。【函数结束前,执行这个defer内容】
defer很多,就会压入堆栈中。后进先出
更多类型
指针
指针保存了值的内存地址。go没有指针运算。
&操作符会生成一个指向其操作数的指针。&i获得i的内存地址,如0xc000090000*操作符表示通过指针指向变量的值。*后面要加上地址,这能获取这个地址的值,如*(&i)=i,都是i的值。
p := &i中的p是i的地址,*p是顺着地址找到了i的值
结构体
一个结构体(struct)就是一组字段(field)。
【感觉是数组的升级版,数组只能全部是一个类型,而结构体可以不同东西有不同类型】
数组
类型 [n]T 表示拥有 n 个 T 类型的值的数组。
var a [10]int,表示将变量 a 声明为拥有 10 个整数的数组。
数组不能改变大小。长度是其类型的一部分
【感觉channel就是数组做出来的】
切片
引用一部分数组。它并不存储任何数据,它只是引用了底层数组中的一段。
更改切片的元素会修改其底层数组中对应的元素。【直接通过指针改变了对应的值】
类型 []T 表示一个元素类型为 T 的切片。
a[1:4]包含数组 a 中下标从 1 到 3 的元素。和python一样,不写就默认是上下界。
除了用[1:4]来切片,还可以用无长度的数组来创建
切片的长度和容量
切片s,长度是len(s),容量是cap(s)。
左指针改容量,右指针不改容量。因为切片的index必须是一个非负数,所以取不到-1,所以左指针就规定了容量。
容量,也就是可能取到的长度。
长度是切片的内容长度,容量是从左边指针的切片开始算起的。

切片的零值
切片的零值是 nil。nil 切片的长度和容量为 0 且没有底层数组。
make创建切片
切片追加元素append
append 内建函数将元素追加到切片的末尾。 若它有足够的容量,其目标就会重新切片以容纳新的元素。否则,就会分配一个新的基本数组。 append 返回更新后的切片。因此必须存储追加后的结果,通常为包含该切片自身的变量:
作为一种特殊的情况,将字符追加到字节数组之后是合法的,就像这样:
Go的数组是值语义。一个数组变量表示整个数组,它不是指向第一个元素的指针(不像 C 语言的数组)。
当一个数组变量被赋值或者被传递的时候,实际上会复制整个数组。【js当中也是这样,重新赋值一个值,如string,相当于照样新建了一个值。与原来的毫无关系。js参考】
(为了避免复制数组,你可以传递一个指向数组的指针,但是数组指针并不是数组。)
可以将数组看作一个特殊的struct,结构的字段名对应数组的索引,同时成员的数目固定。
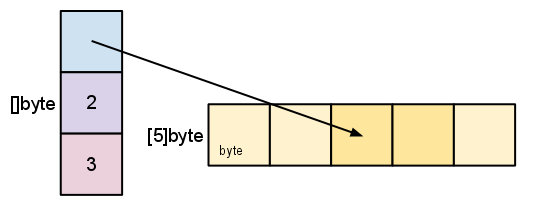
切片的内幕一个切片是一个数组片段的描述。它包含了指向数组的指针,片段的长度, 和容量(片段的最大长度)。
make([]byte, 5)相当于
s = s[2:4]
切片操作并不复制切片指向的元素。它创建一个新的切片并复用原来切片的底层数组。【改变头的指针地址】
通过一个新切片修改元素会影响到原始切片的对应元素。
切片的生长要增加切片的容量必须创建一个新的、更大容量的切片,然后将原有切片的内容复制到新的切片。
可能的陷阱切片操作并不会复制底层的数组。整个数组将被保存在内存中,直到它不再被引用。
这样的话,有时候可能会因为一个小的内存引用导致保存所有的数据。
【简言之要用切片来操作,而非操作整个数组。感觉切片的出现就是为了避免整个数组的操作】

range
for 循环的 range 形式可遍历切片或映射。
每次迭代都会返回两个值。第一个值为当前元素的下标,第二个值为该下标所对应元素的一份副本。
可以用_来忽略
练习:切片
实现
Pic。它应当返回一个长度为dy的切片,其中每个元素是一个长度为dx,元素类型为uint8的切片。当你运行此程序时,它会将每个整数解释为灰度值(好吧,其实是蓝度值)并显示它所对应的图像。图像的选择由你来定。几个有趣的函数包括
(x+y)/2,x*y,x^y,x*log(y)和x%(y+1)。(提示:需要使用循环来分配
[][]uint8中的每个[]uint8;请使用uint8(intValue)在类型之间转换;你可能会用到math包中的函数。)作者:BigManing 来源:CSDN 原文:https://blog.csdn.net/qq_27818541/article/details/54346106

感觉x^y最好看

映射map
将键映射到值。零值为nil,没有键也不能添加键。
练习:映射
实现
WordCount。它应当返回一个映射,其中包含字符串s中每个“单词”的个数。函数wc.Test会对此函数执行一系列测试用例,并输出成功还是失败。你会发现 strings.Fields 很有帮助。
函数
函数也是值,可以像值一样被传递。
闭包
练习:斐波纳契闭包
方法和接口
方法
就是给结构体加一个方法。
这些都是在值下面增加方法。因此处理的都是输入的值的副本
如果用指针,就是在直接操作值本身。
函数如果需要传入指针(输入有*),那么必须传入(参数&,不然报错)
而type下面的方法就不需要,解释器会默认处理好。
一般都是传地址,复制值成本太高
接口
一个防御输入值为nil的方法:
如果值是nil,那么调用其底下方法,就会产生panic报错。
因为不知道该用哪个类型的方法。【可能因为nil下面并没有这个方法】
类型断言
语法:t := i.(T),断言i为T类型。
类型选择
从几个类型断言中选择分支的结构。
就是一种根据不同输入类型来选择操作的switch结构。类型用type表示
stringer
fmt默认的打印方法,是调用结构体下面的String() 方法。
因此可以通过修改String()的方法,来修改该结构体的打印值。
【感觉这种能操纵默认方法的操作,非常有毒】
练习:Stringer
输入IPAddr{1, 2, 3, 4} 打印为 "1.2.3.4"。
go似乎不能直接对数组进行操作,这是一个不可变的东西。而又查到了,可以对string进行split和join。
因此一开始的想法,是把数组一个个拿出来转成string,然后再进行split和join成想要的地址样子。
不过byte转string,能查到的方法,只有在前面加一个string(),如string(p)。但这个仅对[]byte类型有用,而这里的p的类型是IPAddr,所以就不能用。
查到了这个方法来解决:
作者:BigManing 来源:CSDN 原文:https://blog.csdn.net/qq_27818541/article/details/54347335
感觉加点可以不用那么麻烦,最后删掉一位字符串即可
不过go里面的数组都是值,是不可变的,因此字符串拼接的操作,其实是创建了一个新的字符串,其值是两个字符串拼接的而已。包括最后的切一位,也是生成了一个新的字符串。
也就是说,循环了len(p)次数,意味着产生了len(p)个字符串,不过之前的都被废弃了,只剩下最后一个而已。换言之这对内存成本很高。
然后发现了一个绕过拼接字符串的方法。
主要是Sprintf这个函数的操作。参考
错误
error 类型是一个内建接口
error 为 nil 时表示成功;非 nil 的 error 表示失败。
练习:错误
ErrNegativeSqrt(x)是把x从float64转成ErrNegativeSqrt。
作为error输出的时候,会优先调用Error()来打印。然而这个函数返回的也是一个打印,因此如果用e本身,就会触发死循环。得转换一下格式才行。
reader
一次读取多少字节
练习:reader
不是很懂这个😂😂
练习:rot13Reader
就是用reader解密咯。加密方法是ROT13。用一遍加密,再用一遍解密。因为就是把字母替换为其13位后面的字母。
图像
image包
练习:图像

并发
go routine
goroutine是由 Go 运行时管理的轻量级线程。
会启动一个新的 Go 程并执行
在新的 Go 程中只负责执行 f ,其他的求值发生在当前的 Go 程中。
Go 程在相同的地址空间中运行,因此在访问共享的内存时必须进行同步。
信道
信道是带有类型的管道,你可以通过它用信道操作符 <- 来发送或者接收值。
(“箭头”就是数据流的方向。)
和映射与切片一样,信道在使用前必须创建:
默认情况下,发送和接收操作在另一端准备好之前都会阻塞。这使得 Go 程可以在没有显式的锁或竞态变量的情况下进行同步。
如果计算量小的话,就会在第二个协程开启前,就已经把第一个协程内容删掉了
带缓冲的信道
make初始化信道,第二个参数是缓冲长度
仅当信道的缓冲区填满后,向其发送数据时才会阻塞。当缓冲区为空时,接受方会阻塞。
【满了不让塞,空了不让拿】
range 和 close
发送者可通过 close 关闭一个信道来表示没有需要发送的值了。
接收者可以通过为接收的第二个参数,来判断信道是否被关闭:若没有值可以接收且信道已被关闭,那么在执行完
之后 ok 会被设置为 false。
循环 for i := range c 会不断从信道接收值,直到它被关闭。
注意: 只有发送者才能关闭信道,而接收者不能。向一个已经关闭的信道发送数据会引发程序恐慌(panic)。
还要注意: 信道与文件不同,通常情况下无需关闭它们。只有在必须告诉接收者不再有需要发送的值时才有必要关闭,例如终止一个 range 循环。
select
select 语句使一个 Go 程可以等待多个通信操作。
select 会阻塞到某个分支可以继续执行为止,这时就会执行该分支。当多个分支都准备好时会随机选择一个执行。
可以用struct{}改写,这样省内存空间。
默认选择
为了在尝试发送或者接收时不发生阻塞,可使用 default 分支:
练习:等价二叉查找树
树的结构是这样的:
要写一个walk函数,来一个个把树的内容传到信道里面,然后用same函数来比较两个树是否一样。
// 原文链接:https://blog.csdn.net/qq_27818541/article/details/54411990
sync.Mutex
若想避免冲突,保证每次只有一个 Go 程能够访问一个共享的变量,从而
这里涉及的概念叫做 互斥(mutualexclusion) ,我们通常使用 互斥锁(Mutex)* 这一数据结构来提供这种机制。
Go 标准库中提供了 sync.Mutex 互斥锁类型及其两个方法:
Lock
Unlock
我们可以通过在代码前调用 Lock 方法,在代码后调用 Unlock 方法来保证一段代码的互斥执行。 我们也可以用 defer 语句来保证互斥锁一定会被解锁
web爬虫
Last updated
Was this helpful?